DRUID 7.8
Deployment Dates
The table below lists the deployment date of DRUID v7.8 across DRUID Clouds. To view the DRUID Releases Calendar, see Druid AI Releases.
|
Druid Cloud Community *.community.Druidplatform.com |
Druid Cloud US *.us.Druidplatform.com |
Druid Cloud Australia *au.Druidplatform.com |
Druid Cloud West-Europe (PROD) *.Druidplatform.com |
|---|---|---|---|
| May 09, 2024 | June 06, 2024 | June 06, 2024 | June 06, 2024 |
These release notes give you a brief, high-level description of the improvements implemented to existing features.
If you have questions about your DRUID tenant, please contact support@Druidai.com or your local DRUID partner for more information.
What's New
- KB Metadata. We're thrilled to introduce KB Metadata, a powerful addition to our product suite designed to enhance knowledge management capabilities. With KB Metadata, you can seamlessly categorize and organize Knowledge Base (KB) content, ensuring relevance and accuracy in responses generated by the conversational engine. This feature enables efficient linking between KB elements and business objects, providing you with a comprehensive overview of all metadata associated with their data sources.
- Integration Audit Trail - Technological Preview. Available in the Connector Diagram, the Audit Trail provides a comprehensive historical record of all changes made by authors to the integrations (all integration tasks within a connector action). It offers you with the ability to track and review the changes made to integrations.
-
Flow Diagram facelift. We're thrilled to unveil the latest enhancements to our Flow Diagram interface, providing a sleek and intuitive experience for users. In both manual and auto-layout modes, you'll notice significant improvements:
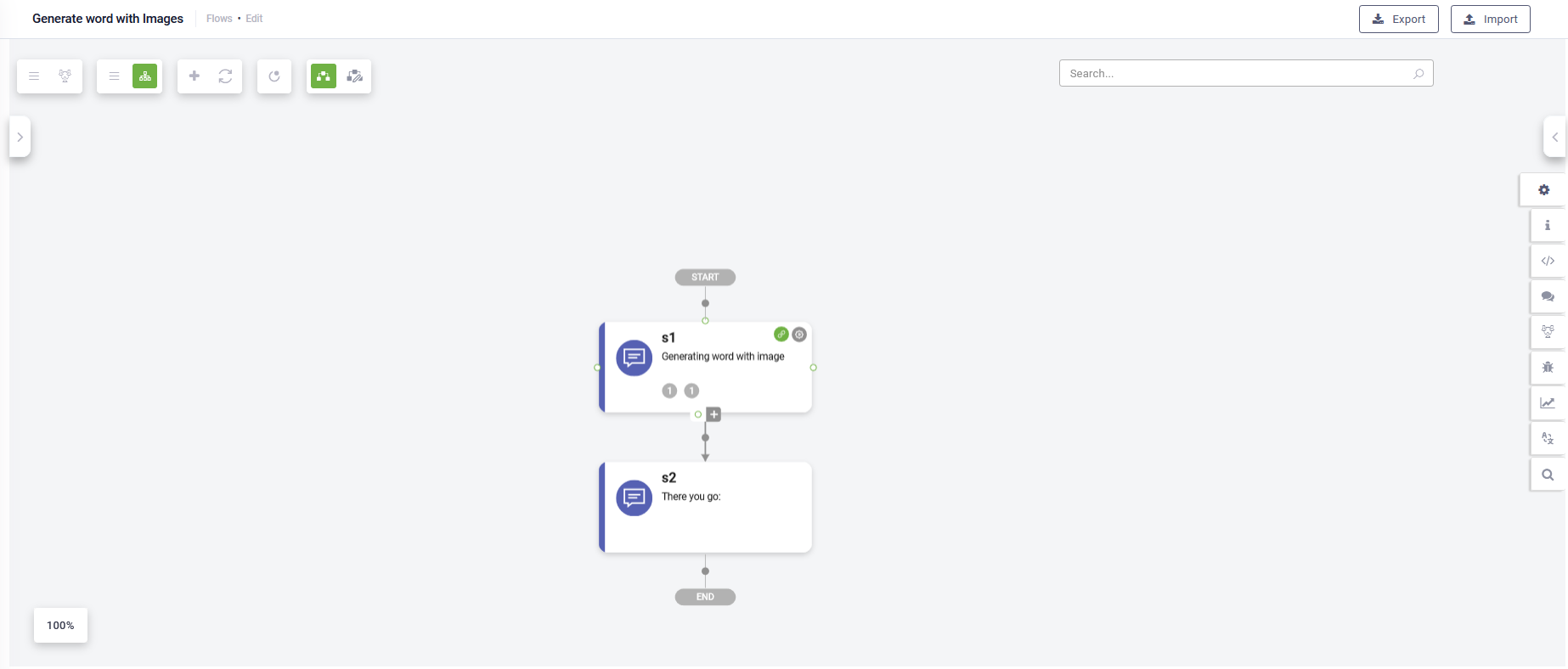
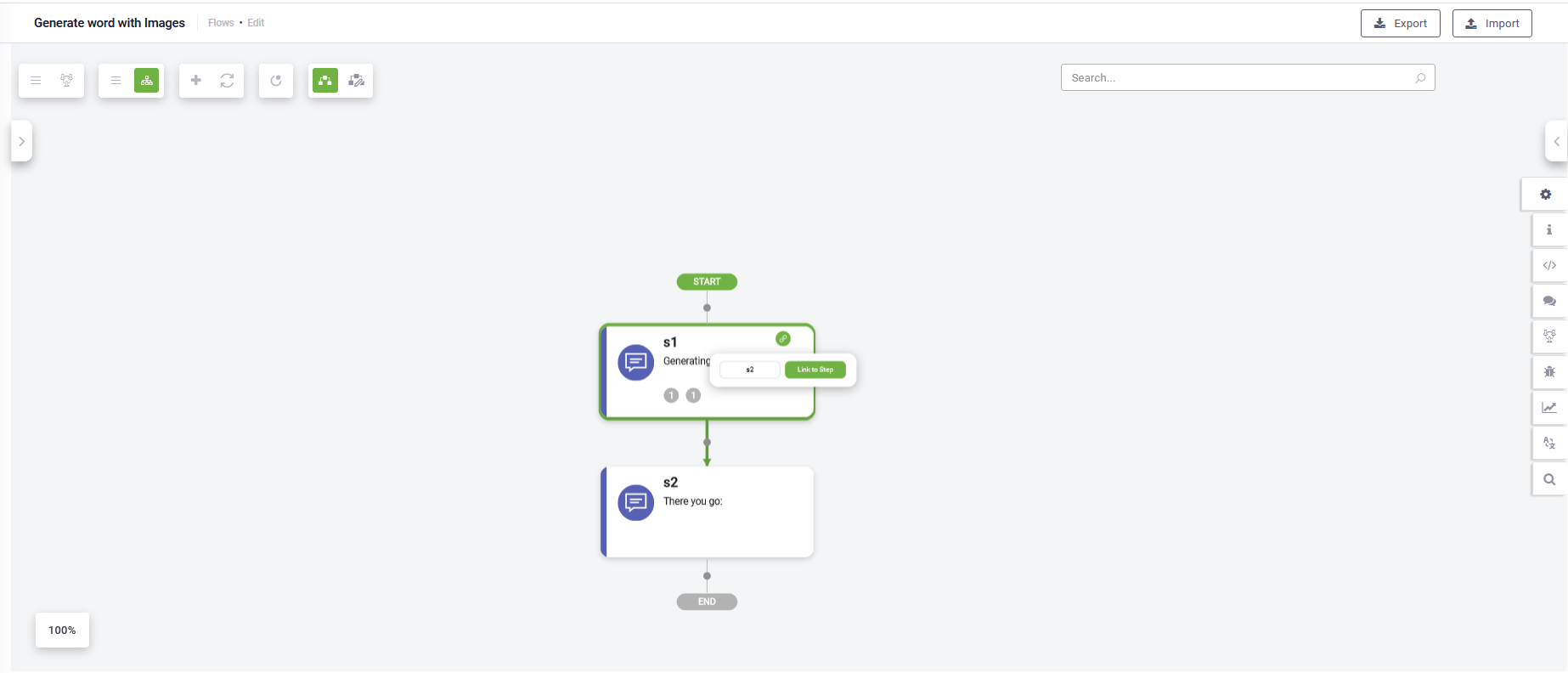
- Redesigned step nodes: Each node now features four ports, accessible upon hover, allowing seamless link creation through drag-and-drop functionality. Additionally, the bottom port shares space with an expanded palette accessible via the plus button. Hovering over the "Link to Step" gear reveals related options.
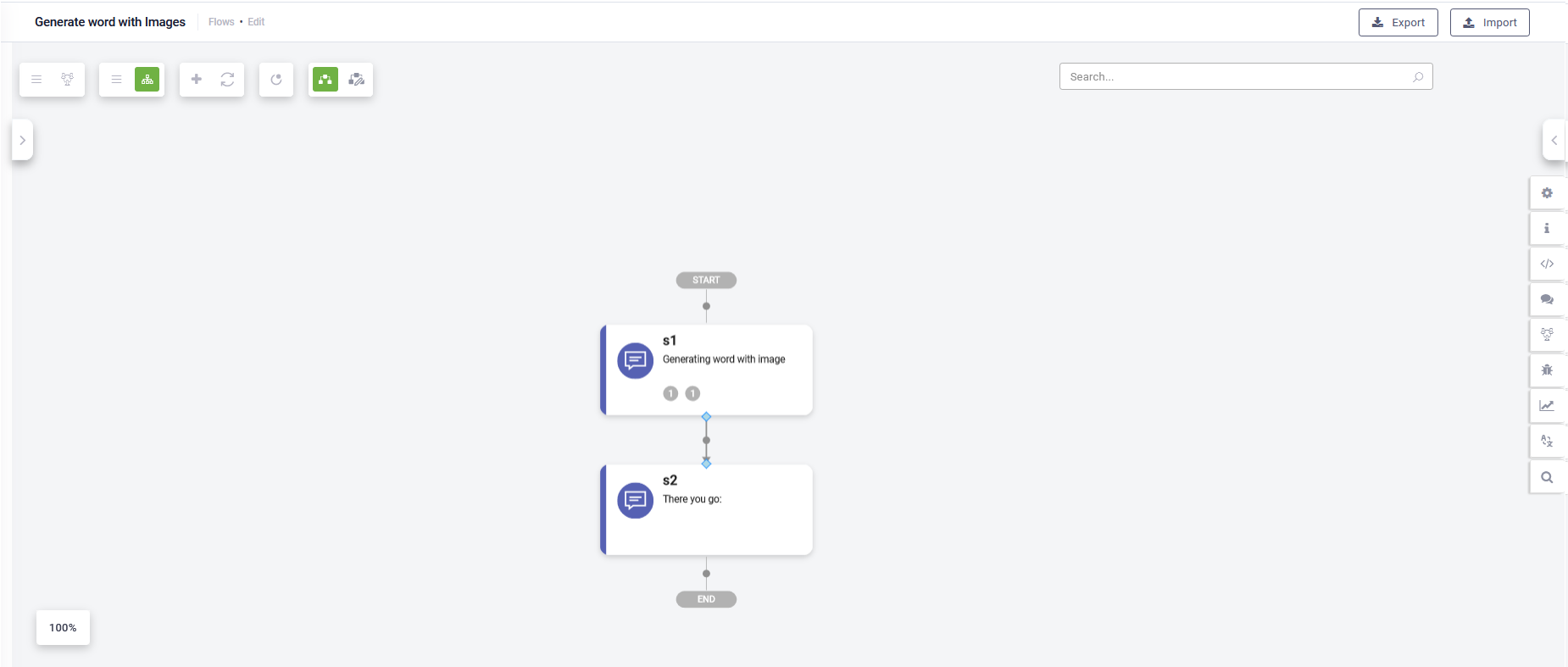
- Enhanced link behavior: Links between steps now default from the bottom port to the top port of the child step, with the flexibility to adjust endpoints to any of the four ports. Circular links begin and end on the right-side port, while exception links start from the right side, indicated by an icon. To reposition endpoints, simply click on the link to reveal blue diamonds for easy adjustment.
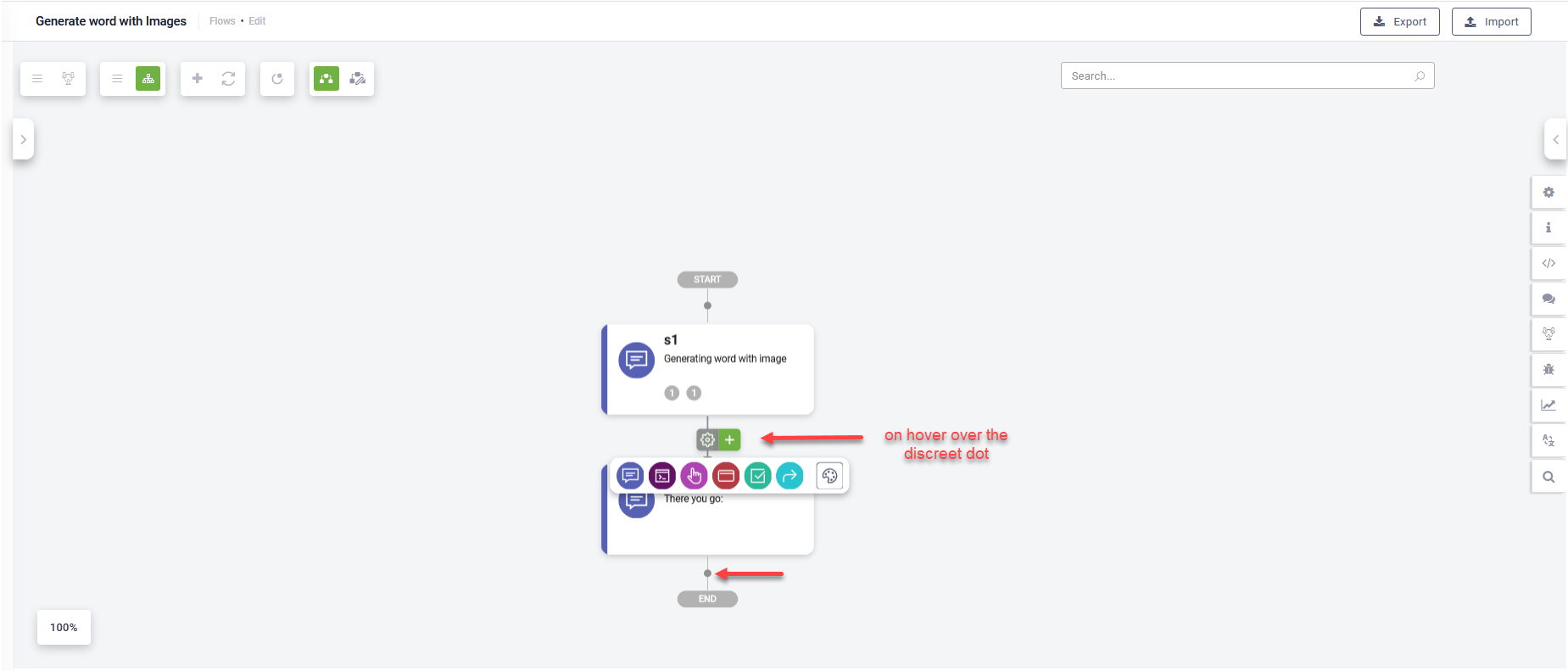
- Streamlined Add / Settings buttons: To optimize space between steps, the Add and Settings buttons now appear upon hover, indicated by a discreet dot when inactive. Despite this change, the functionality of these buttons remain unchanged, ensuring seamless navigation and configuration.
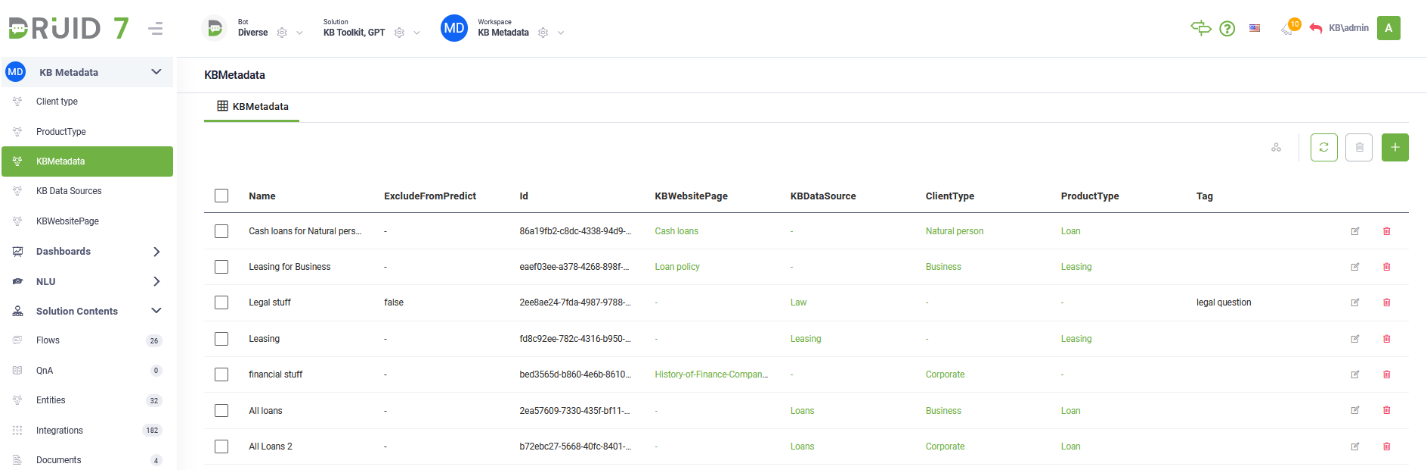
For information on how to use the KB Metadata, see Enhance KB Answers with KB Metadata.
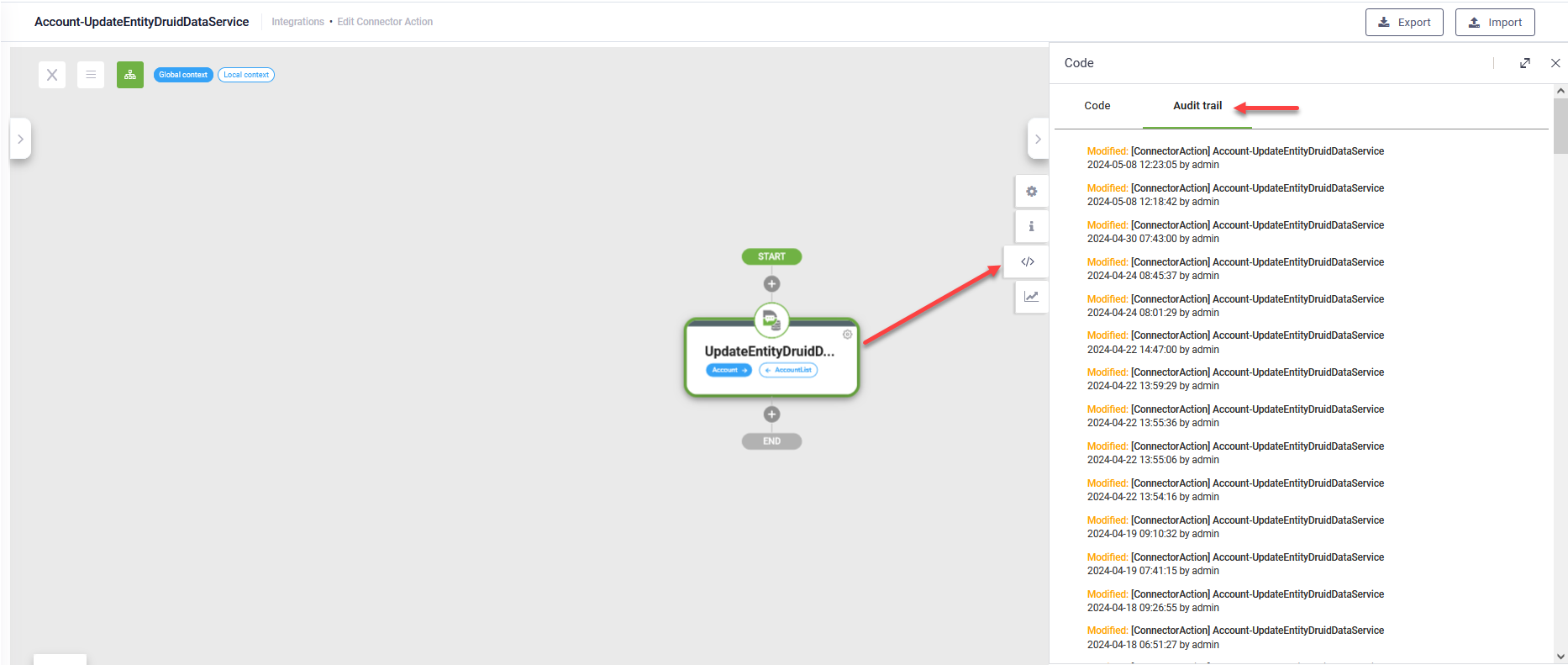
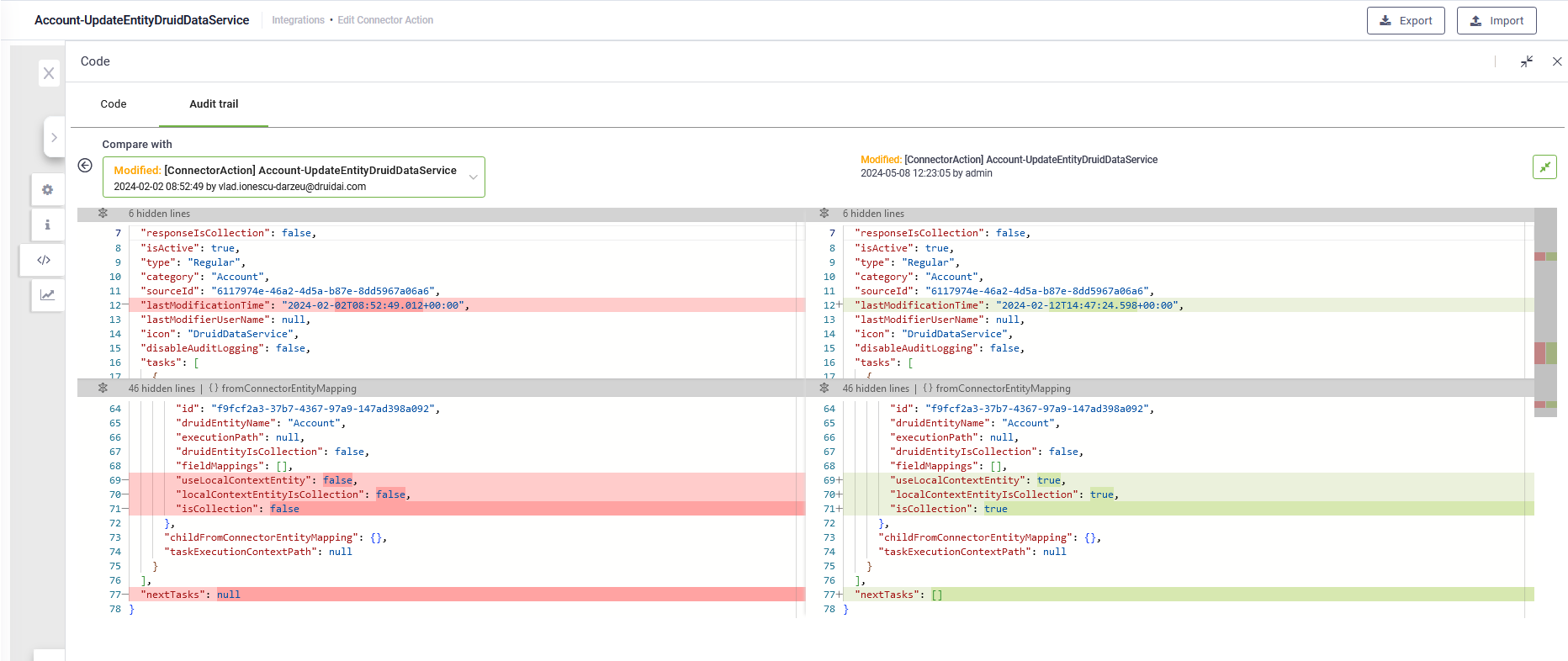
For more information, see Review Integration Changes.
Improvements
- KB improvements. This release introduces several enhancements to the Knowledge Base (KB):
- You can now train the KB even if one or more documents fail extraction.
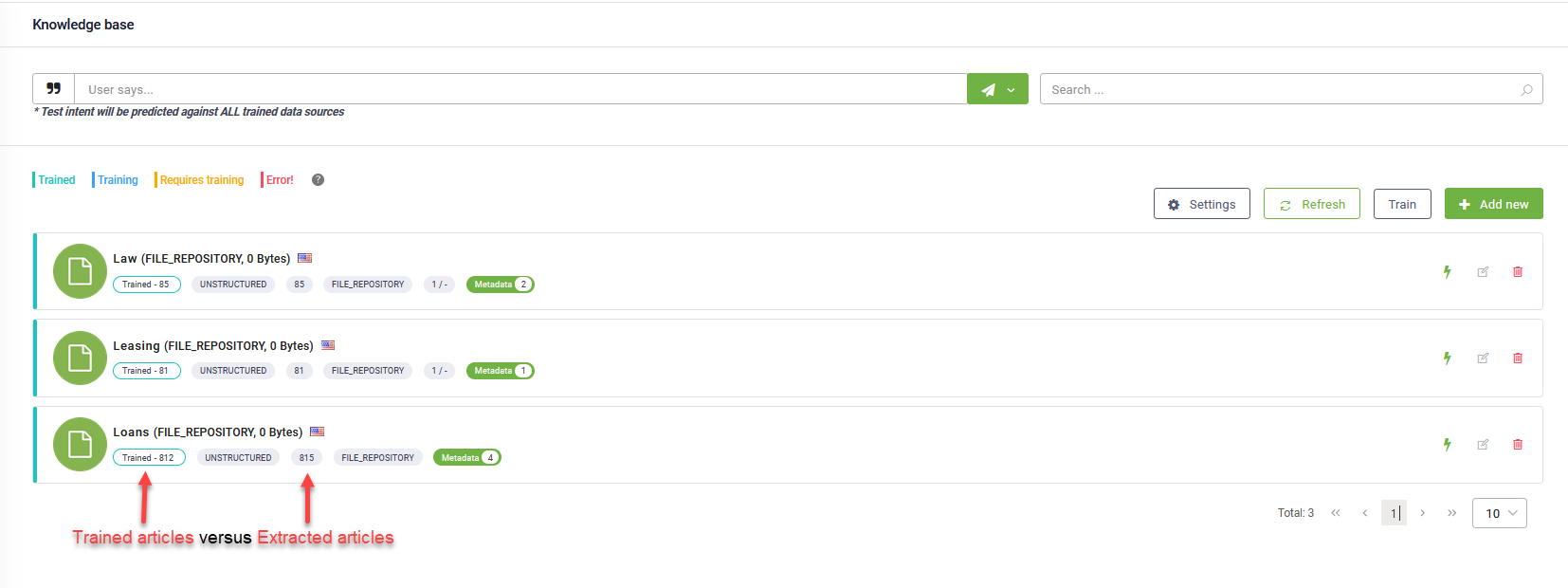
- The Knowledge Base page now displays, for all data sources, the number of trained articles compared to the number of extracted articles per data source. The number of trained articles might exceed the number of extracted articles based on the Text Generator Strategies you have set on the KB.
- Articles are now displayed in the data source content in the order in which they were extracted. Each extracted article now includes the property [[KBRecord]].OrderNumber, allowing you to further manipulate the articles you provide to GPT. For example, you can prioritize the article that is the best match and its neighbors.
-
Improved Website and SharePoint Data Sources. Crawling and extraction processes for website and SharePoint data sources have been separated, offering users enhanced flexibility and control over their data ingestion workflows
-
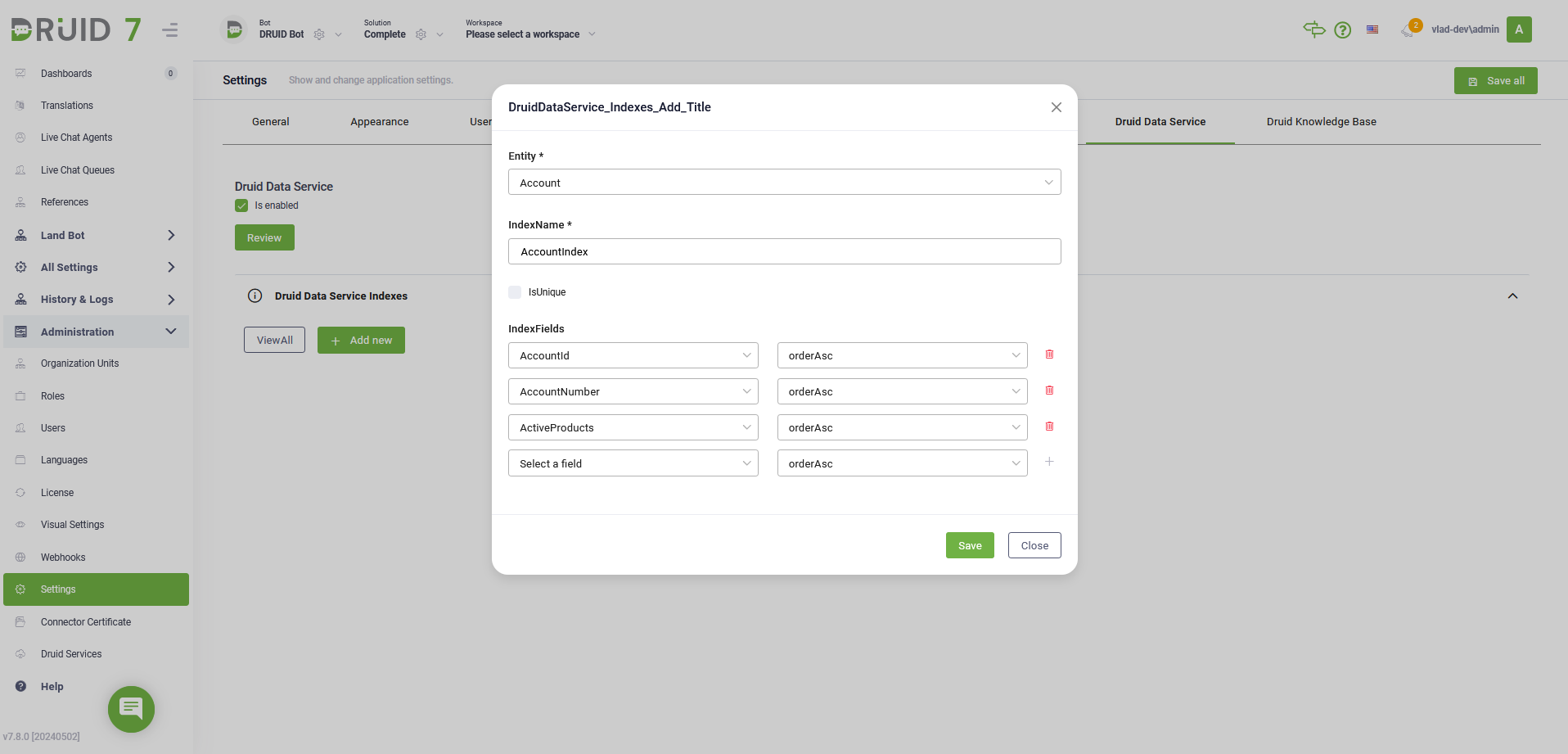
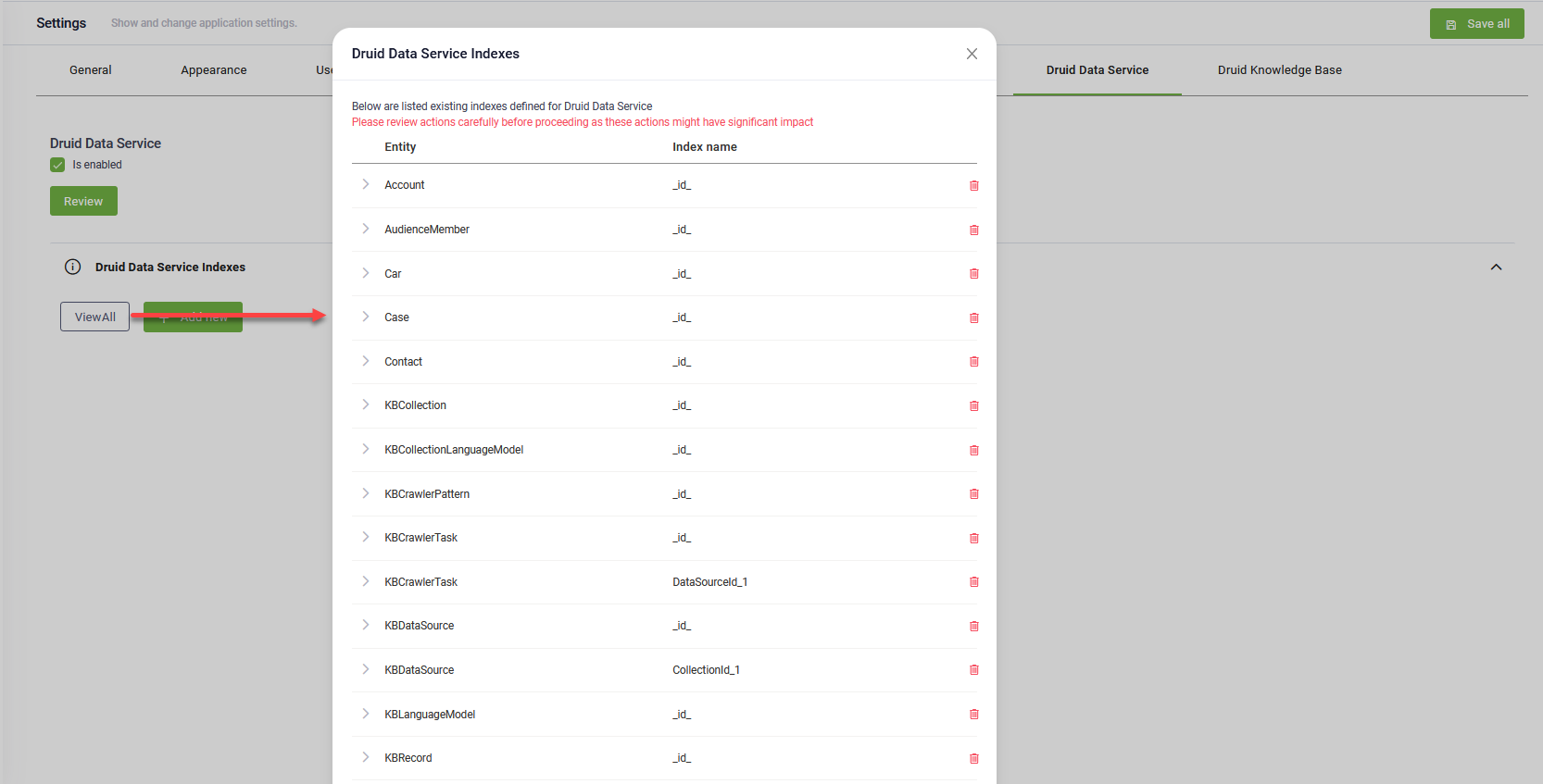
Druid Data Service Indexes. You can now optimize Data Service queries for entities with a large volume of records by adding indexes directly within the DRUID Data Service DB. This enhancement offers improved query performance and greater control over data retrieval, enhancing the efficiency of your DRUID experience.
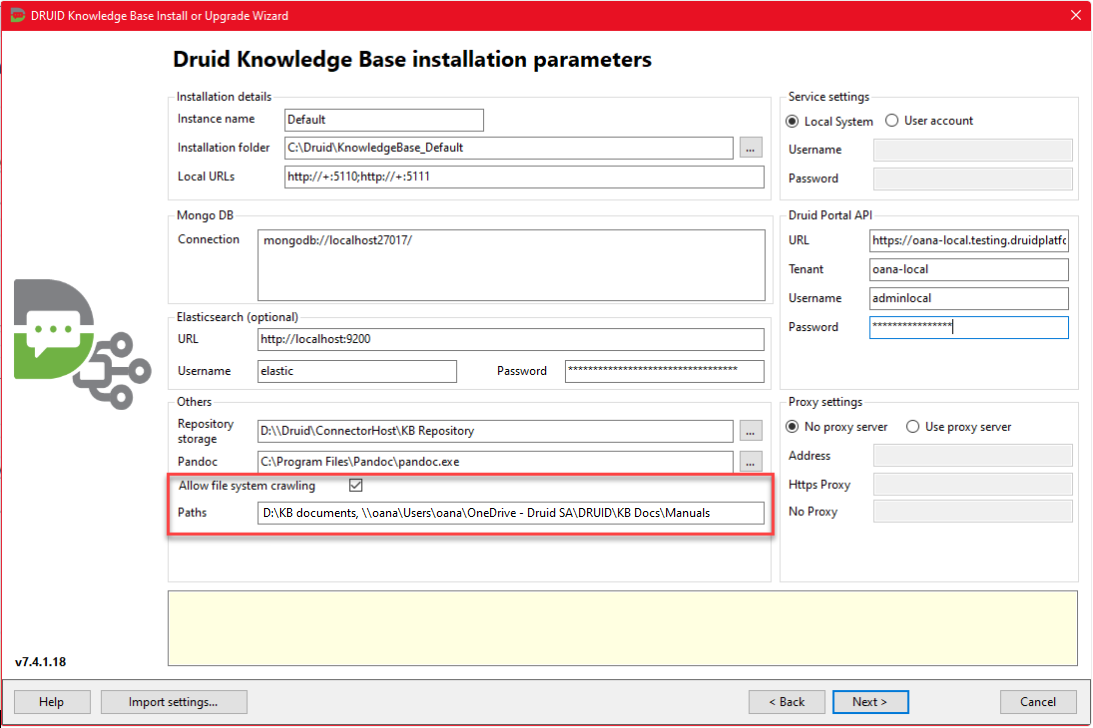
- Enhanced Security for KB On-Premise Installation. In DRUID hybrid deployments, when installing the KB on-premises, users now have the option to enable file system crawling. This feature allows specifying the paths to the network shared drive that the KB Agent is authorized to crawl, separated by commas. By restricting the KB Agent from crawling the entire network shared drive, security is significantly strengthened.
- Flows - support for two-stage Set Variables.We're excited to introduce improved functionality in flows with the addition of support for two-stage set variables. Now, users can efficiently utilize both scalar and entity set variables without the need to add multiple set variables. This enhancement streamlines workflow processes, allowing users to achieve their goals with greater simplicity and effectiveness. However, please note that fields of type entity list are not compatible with these set variable constructions.
- User experience improvement on file upload. Now, when file upload is enabled on the AI Agent and a user attempts to upload a file while the conversation is in Idle mode, a new special message, "FileUploadedInIdle" is triggered. This improvement ensures smoother interaction and provides users with clear feedback when attempting file uploads during Idle mode conversations.
- Oracle Connector - New Parameter Support.We're excited to announce a new enhancement in the Oracle Connector: support for Out Parameters in the 'Connector Field Source Type' for SQL responses. This update enables you to capture the value of an output parameter directly from the result set. For example:
-
Druid Data Service Connector - Query Integrations. We're excited to introduce a new enhancement to the Druid Data Service Connector: the addition of the COUNT(distinct field) function when filtering queries using the DRUID custom query feature. This function allows users to efficiently count the number of distinct (unique) values within a specified column or field, providing greater flexibility and precision in data analysis.
- Enhanced Solution References. In our latest update, we've refined the process of linking entities from Solution References and applying changes. Now, within the "Link Entities and Entity Fields" pop-up, users have the flexibility to select not only the entity fields but also its associated web views, forms, and charts. This enhancement streamlines the workflow, providing users with comprehensive control over entity elements selection for seamless integration into their solutions.
(SELECT Id FROM User WHERE Email = :InitiatorEmail)
RETURNING Id INTO :IdEvent;
select IdEvent from dual;
select
a.FirstName,
count(b.Id) Counter
from Author a
left join Book b on b.AuthorId = a.Id
where a.FirstName = 'Zoe'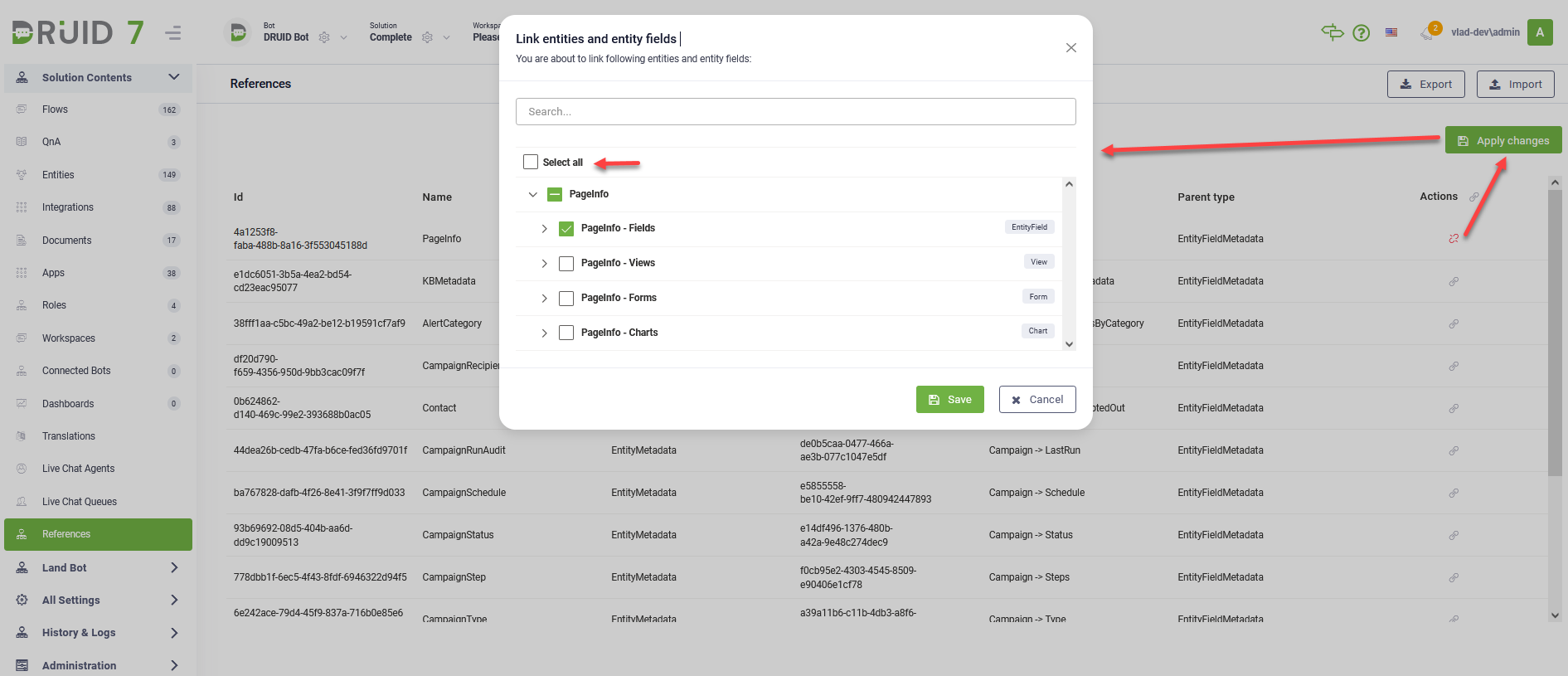
Bug Fixes
- Message Reactions: Message reactions are now appropriately ignored on WhatsApp, WhatsApp Meta, Ring Central, and Sunshine channels, ensuring a seamless user experience without unnecessary clutter.
- REST Connector Custom Authentication: Users can now deselect tasks for custom authentication within the REST Connector, providing greater flexibility and control over authentication processes.
- Druid Data Service Connector (Read Expansion Level 2): The issue with Read Expansion Level 2 not properly loading has been resolved, ensuring accurate and complete data retrieval within the Druid Data Service Connector.
- Druid Data Service Connector (Query Entity): Query Entity now correctly brings children from the selected Expansion level, addressing an issue where data was not being retrieved as expected.